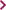<document id="1"> <content> <html xmlns="http://www.w3.org/1999/xhtml"> <head> </head> <body> <div> <ul> <li><a href="http://www.google.de/">http://www.google.de/Google</a> <ul> <li><a href="http://earth.google.de/">Google Earth</a></li> <li><a href="http://picasa.google.de/intl/de/">Picasa</a></li> </ul> </li> <li><a href="http://www.heise.de/">Heise</a></li> <li><a href="http://www.yahoo.de/">Yahoo</a></li> </ul> </div> </body> </html> </content></document>
Sammeln Sie alle Links im Dokument (XHTML-Element vom Typ a, die an den Namensraum http://www.w3.org/1999/xhtml gebunden sind), die zu einem Google-Dienst verweisen. Die Existenz des Textes google innerhalb des href-Attributes entscheidet, ob es sich um einen Google-Dienst handelt. Für den XPath-Ausdruck steht ihnen der Präfix x für den Namensraum http://www.w3.org/1999/xhtml zur Verfügung.
a
http://www.w3.org/1999/xhtml
 Alle Links eines Dokuments selektieren
Alle Links eines Dokuments selektieren