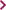<document id="1"> <content> <html xmlns="http://www.w3.org/1999/xhtml"> <head> </head> <body> <div> <ul> <li><a href="http://www.google.de/">http://www.google.de/Google</a> <ul> <li><a href="http://earth.google.de/">Google Earth</a></li> <li><a href="http://picasa.google.de/intl/de/">Picasa</a></li> </ul> </li> <li><a href="http://www.heise.de/">Heise</a></li> <li><a href="http://www.yahoo.de/">Yahoo</a></li> </ul> </div> </body> </html> </content></document>
Collect all links in the document (XHTML elements of type a, which are attached to the namespace http://www.w3.org/1999/xhtml) which refer to a Google service. The existence of the text “google” within the href-attribute decides whether a Google service is concerned. For the XPath expression, the prefix x is available for the namespace “http://www.w3.org/1999/xhtml”.
 Selecting all links of a document
Selecting all links of a document